I Built a GPU Emulator That Predicts Performance Without Running Code
We needed to test our CUDA kernels on 15 different GPUs. The problem? Renting all of them costs $3,000 a month. Just for testing.
That's when we thought: what if we could predict how a kernel runs on any GPU without actually owning it?
Not some rough guess. Real numbers. Like, your kernel takes 2.4ms on an RTX 4090 and 5.1ms on a V100. Within 1% of actual hardware.
Three months later, we built it. Now developers test kernels on 50+ GPUs before writing a single line. One team saved $18,000 in cloud costs. Another found a bug on an A100 they've never even touched.
Here's how it works:
The problem: Testing is expensive
┌──────────────────────────────────────────────────────────────┐ │ The Multi-GPU Testing Problem │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Scenario: Test kernel on 15 different GPUs │ │ │ │ Cloud rental costs (per month): │ │ • H100 (80GB): $2.50/hour → $1,800/month │ │ • A100 (80GB): $1.10/hour → $792/month │ │ • RTX 4090: $0.80/hour → $576/month │ │ • V100 (32GB): $0.75/hour → $540/month │ │ • RTX 3080: $0.40/hour → $288/month │ │ • T4: $0.35/hour → $252/month │ │ • RTX 2080 Ti: $0.30/hour → $216/month │ │ ... and 8 more GPUs │ │ │ │ Total monthly cost: ~$7,500 │ │ Annual cost: $90,000 │ │ │ │ For a startup? Impossible. │ │ │ └──────────────────────────────────────────────────────────────┘
You're building a CUDA library. Your users have everything from RTX 2060s to H100s. Your kernel runs great on your RTX 4090. Then someone with a V100 complains it's slow. You've never even seen a V100.
The usual answer? Rent them all. $7,500 a month. For a small team, that's just not realistic. So you test on one or two GPUs and cross your fingers. Then the bug reports start coming in.
What we built instead
We built a simulator. You give it your kernel code. It tells you exactly how it runs on any GPU. H100, A100, RTX 4090, V100, whatever. Without running a single line of actual code.
NVIDIA has simulators. They're internal only. There are academic tools too. But they all have the same problems:
- You can't use them
- They take forever to set up
- They're slow (hours per kernel)
- They're wrong (20-30% error)
We wanted something that works in seconds, needs zero setup, and is actually right.
How it works
We built three different emulators. Each one gets more accurate but needs more information. The system picks the best one for your kernel:
┌──────────────────────────────────────────────────────────────┐ │ Tier 1: NeuSight Tile-Based Emulator (99% accuracy) │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Method: Decompose execution into tiles │ │ • Break kernel into L2-cache-sized tiles │ │ • Simulate each tile with architectural models │ │ • Account for occupancy, bandwidth, latency │ │ • Apply architecture-specific corrections │ │ │ │ Accuracy: 98-99% on most kernels │ │ Speed: 100-500ms per emulation │ │ Coverage: All kernels with source code │ │ │ │ Key insight: Tile size based on actual GPU L2 cache │ │ → Hopper H100: 96MB L2 → Large tiles │ │ → Pascal P100: 4MB L2 → Small tiles │ │ │ └──────────────────────────────────────────────────────────────┘
Tier 1: NeuSight Emulator is the main one. It breaks your kernel into tiles that match the GPU's L2 cache size. Then it simulates each tile. For each one, we figure out:
- How many warps can run at once (based on registers and shared memory)
- How fast memory moves (checking if your accesses are coalesced)
- How many TFLOPs you're actually getting
- How blocks get scheduled across waves
The trick is we use real GPU specs. When simulating an H100, we use its actual 132 SMs, 96MB L2 cache, 3.35TB/s bandwidth. For a GTX 1060, we use 10 SMs, 1.5MB L2, 192GB/s. No fake numbers. Everything comes from NVIDIA's datasheets and our own measurements.
┌──────────────────────────────────────────────────────────────┐ │ Tier 2: NCU Baseline Emulator (Hardware-authentic scaling) │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Method: Scale from real NCU baseline measurements │ │ • Start with real NCU data from a reference GPU │ │ • Apply architectural scaling factors │ │ • Adjust for compute capability differences │ │ │ │ Accuracy: 95-98% when baseline available │ │ Speed: 50-200ms per emulation │ │ Coverage: Kernels with NCU baseline data │ │ │ │ Architecture scaling factors: │ │ • Hopper: 1.05x compute, 1.00x memory │ │ • Ada Lovelace: 1.00x compute, 0.95x memory │ │ • Ampere: 0.92x compute, 0.90x memory │ │ • Turing: 0.85x compute, 0.85x memory │ │ • Volta: 0.88x compute, 0.88x memory │ │ • Pascal: 0.75x compute, 0.80x memory │ │ │ └──────────────────────────────────────────────────────────────┘
Tier 2: NCU Baseline Emulator is different. If you already profiled your kernel on one GPU (say, your RTX 4090), we take those real numbers and scale them to other GPUs. We have scaling factors for every architecture. Hopper is 1.05x faster at compute than Ada. Ampere is 0.92x. We measured all of this.
This is fast and really accurate because we start with real hardware data, not a simulation.
┌──────────────────────────────────────────────────────────────┐ │ Tier 3: Analytical Emulator (Fast estimates) │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Method: Mathematical roofline model │ │ • Calculate compute intensity (FLOPs/byte) │ │ • Determine if memory or compute bound │ │ • Apply quick heuristics for divergence, coalescing │ │ │ │ Accuracy: 85-92% (rougher but fast) │ │ Speed: 10-50ms per emulation │ │ Coverage: All kernels, even without code │ │ │ │ When used: Fallback when other tiers unavailable │ │ │ │ Ridge point calculation: │ │ ridge = peakTFLOPS / memoryBandwidthGBps │ │ if (arithmeticIntensity < ridge) → memory bound │ │ if (arithmeticIntensity >= ridge) → compute bound │ │ │ └──────────────────────────────────────────────────────────────┘
Tier 3: Analytical Emulator is the backup. It uses math (roofline model) to figure out if your kernel is memory-bound or compute-bound. Less accurate (85-92%) but super fast. And it works even if we don't have your source code.
The database
All three emulators use the same database. We scraped specs for 50+ NVIDIA GPUs. Every generation from Hopper down to Pascal:
┌──────────────────────────────────────────────────────────────┐ │ GPU Architecture Database (excerpt) │ ├──────────────────────────────────────────────────────────────┤ │ │ │ H100 (Hopper, sm_90): │ │ • 132 SMs, 96MB L2, 3.35TB/s bandwidth, 67 TFLOPs FP32 │ │ • Max occupancy: 64 warps/SM, 2048 threads/SM │ │ • Shared memory: 228KB/SM │ │ │ │ RTX 4090 (Ada Lovelace, sm_89): │ │ • 128 SMs, 72MB L2, 1.01TB/s bandwidth, 82.6 TFLOPs FP32 │ │ • Max occupancy: 48 warps/SM, 1536 threads/SM │ │ • Shared memory: 100KB/SM │ │ │ │ A100 (Ampere, sm_80): │ │ • 108 SMs, 40MB L2, 1.55TB/s bandwidth, 19.5 TFLOPs FP32 │ │ • Max occupancy: 64 warps/SM, 2048 threads/SM │ │ • Shared memory: 164KB/SM │ │ │ │ V100 (Volta, sm_70): │ │ • 80 SMs, 6MB L2, 900GB/s bandwidth, 15.7 TFLOPs FP32 │ │ • Max occupancy: 64 warps/SM, 2048 threads/SM │ │ • Shared memory: 96KB/SM │ │ │ │ GTX 1060 (Pascal, sm_61): │ │ • 10 SMs, 1.5MB L2, 192GB/s bandwidth, 4.4 TFLOPs FP32 │ │ • Max occupancy: 64 warps/SM, 2048 threads/SM │ │ • Shared memory: 96KB/SM │ │ │ │ ... and 45+ more GPUs │ │ │ └──────────────────────────────────────────────────────────────┘
Got all this from NVIDIA's whitepapers and my own testing. For each GPU:
- How many SMs and what compute capability
- Peak FLOPs for FP32, FP16, INT8
- Memory bandwidth and cache sizes
- Max occupancy
- Special features
Proving it works
Building the emulator was hard. Proving it's accurate was harder. We needed real data to compare against.
┌──────────────────────────────────────────────────────────────┐ │ Validation Methodology │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Step 1: Build test kernel suite │ │ • Matrix multiplication (varying tile sizes) │ │ • Reductions (varying patterns) │ │ • Stencil operations │ │ • Memory-bound kernels │ │ • Compute-bound kernels │ │ • Mixed workloads │ │ Total: 47 representative kernels │ │ │ │ Step 2: Profile on real hardware │ │ • Run each kernel on 12 different GPUs │ │ • Capture NCU metrics: execution time, SM efficiency, etc. │ │ • Record actual hardware measurements │ │ │ │ Step 3: Run emulator predictions │ │ • Emulate each kernel on all 50+ GPUs │ │ • Compare predicted vs actual for the 12 we have │ │ │ │ Step 4: Calculate error rates │ │ • Mean Absolute Percentage Error (MAPE) │ │ • Per-kernel accuracy breakdown │ │ • Identify systematic biases │ │ │ └──────────────────────────────────────────────────────────────┘
We wrote 47 test kernels. Matrix multiply, reductions, convolutions, all the common patterns. Then we profiled each one on 12 real GPUs (borrowed some, rented others, bought a few).
Then ran the emulator on all of them. Compared predictions to reality.
┌──────────────────────────────────────────────────────────────┐ │ Accuracy Results (NeuSight Tier 1) │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Execution Time Prediction: │ │ • Mean error: 1.2% │ │ • 95th percentile error: 4.8% │ │ • Worst case: 8.2% (edge case: tiny kernel with overhead) │ │ │ │ SM Efficiency Prediction: │ │ • Mean error: 2.1% │ │ • 95th percentile error: 5.3% │ │ │ │ Memory Throughput Prediction: │ │ • Mean error: 3.4% │ │ • 95th percentile error: 7.1% │ │ │ │ Occupancy Prediction: │ │ • Mean error: 0.8% (nearly perfect - this is analytical) │ │ • 95th percentile error: 2.1% │ │ │ │ Overall: 98-99% accuracy on most kernels │ │ │ └──────────────────────────────────────────────────────────────┘
Results: 98-99% accurate on execution time. Occupancy prediction is basically perfect. SM efficiency within 2-3%.
What you can do with this
This changes how you develop CUDA code:
Test on GPUs you don't own. You have an RTX 4090. Your customer has a V100. Emulate on V100 first. Find out your block size is wrong. Fix it before they ever see it.
┌──────────────────────────────────────────────────────────────┐ │ Case Study: Library Maintainer │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Problem: Maintaining CUDA library for 20+ GPU models │ │ Cost before emulator: $4,500/month in cloud rentals │ │ │ │ With emulator: │ │ • Test all 20 GPUs in RightNow AI: $0 │ │ • Only rent GPUs for final validation: $300/month │ │ • Annual savings: $50,400 │ │ │ │ Bugs caught: │ │ • Ampere occupancy issue (would've affected 30% of users) │ │ • Pascal memory alignment bug (would've crashed on GTX 10x) │ │ • Turing shared memory bank conflict (20% slowdown) │ │ │ └──────────────────────────────────────────────────────────────┘
Optimize for expensive GPUs. H100s cost $30,000. You're not buying one. But emulate it, tune your kernel, and when your customer runs it on their H100 cluster, it already flies.
Catch regressions before commit. Changed your kernel? Emulate across 15 GPUs in 30 seconds. See your change killed Turing performance but helped Ampere. Decide if the tradeoff is worth it.
┌──────────────────────────────────────────────────────────────┐ │ Developer Workflow Transformation │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Before Emulator: │ │ 1. Write kernel │ │ 2. Test on local GPU (RTX 4090) │ │ 3. Deploy to production │ │ 4. Users report issues on V100, A100, etc. │ │ 5. Rent GPUs to debug │ │ 6. Fix and re-deploy │ │ Time: 2-3 days, Cost: $200-500 │ │ │ │ After Emulator: │ │ 1. Write kernel │ │ 2. Test on local GPU (RTX 4090) │ │ 3. Emulate on 15 target GPUs (2 minutes) │ │ 4. Fix issues found in emulation │ │ 5. Deploy with confidence │ │ 6. Zero user-reported GPU-specific bugs │ │ Time: 30 minutes, Cost: $0 │ │ │ └──────────────────────────────────────────────────────────────┘
The hard parts
Reading your kernel automatically
The emulator needs to understand your code without you explaining it:
- Are your memory accesses coalesced?
- Do your branches diverge?
- What's your arithmetic intensity?
- How do you use shared memory?
We built a pattern matcher. It looks for common CUDA idioms:
┌──────────────────────────────────────────────────────────────┐ │ Kernel Pattern Detection │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Coalesced memory access: │ │ Pattern: data[blockIdx.x * blockDim.x + threadIdx.x] │ │ → High coalescing factor: 0.9 │ │ │ │ Strided access: │ │ Pattern: data[threadIdx.y * stride + threadIdx.x] │ │ → Medium coalescing: 0.4 │ │ │ │ Divergent branching: │ │ Pattern: if (threadIdx.x < threshold) │ │ → Divergence probability: 0.5 │ │ │ │ Shared memory usage: │ │ Pattern: __shared__ float tile[TILE_SIZE][TILE_SIZE] │ │ → Shared memory optimization detected │ │ │ └──────────────────────────────────────────────────────────────┘
Different architectures behave differently
Hopper has thread block clusters. Ampere has async memory copy. Volta has independent thread scheduling. Each needs its own model.
We use correction factors. Hopper kernels with shared memory get a 15% speedup in the simulation because Hopper's shared memory is actually faster.
Wave scheduling is tricky
GPUs run blocks in waves. 100 blocks, but only 80 fit? That's 2 waves. The second wave is smaller, so SMs sit idle. The emulator has to account for this waste.
┌──────────────────────────────────────────────────────────────┐ │ Wave Scheduling Example │ ├──────────────────────────────────────────────────────────────┤ │ │ │ GPU: RTX 4090 (128 SMs) │ │ Kernel: 512 blocks, 256 threads/block │ │ Active blocks/SM: 3 │ │ │ │ Total concurrent blocks: 128 SMs × 3 = 384 blocks │ │ Total blocks needed: 512 │ │ │ │ Wave 1: 384 blocks (100% utilization) │ │ Wave 2: 128 blocks (33% utilization - imbalance!) │ │ │ │ Execution time: │ │ = (wave1_time + wave2_time * (128/384)) │ │ = (2.1ms + 2.1ms * 0.33) │ │ = 2.79ms │ │ │ │ Emulator must account for this imbalance penalty │ │ │ └──────────────────────────────────────────────────────────────┘
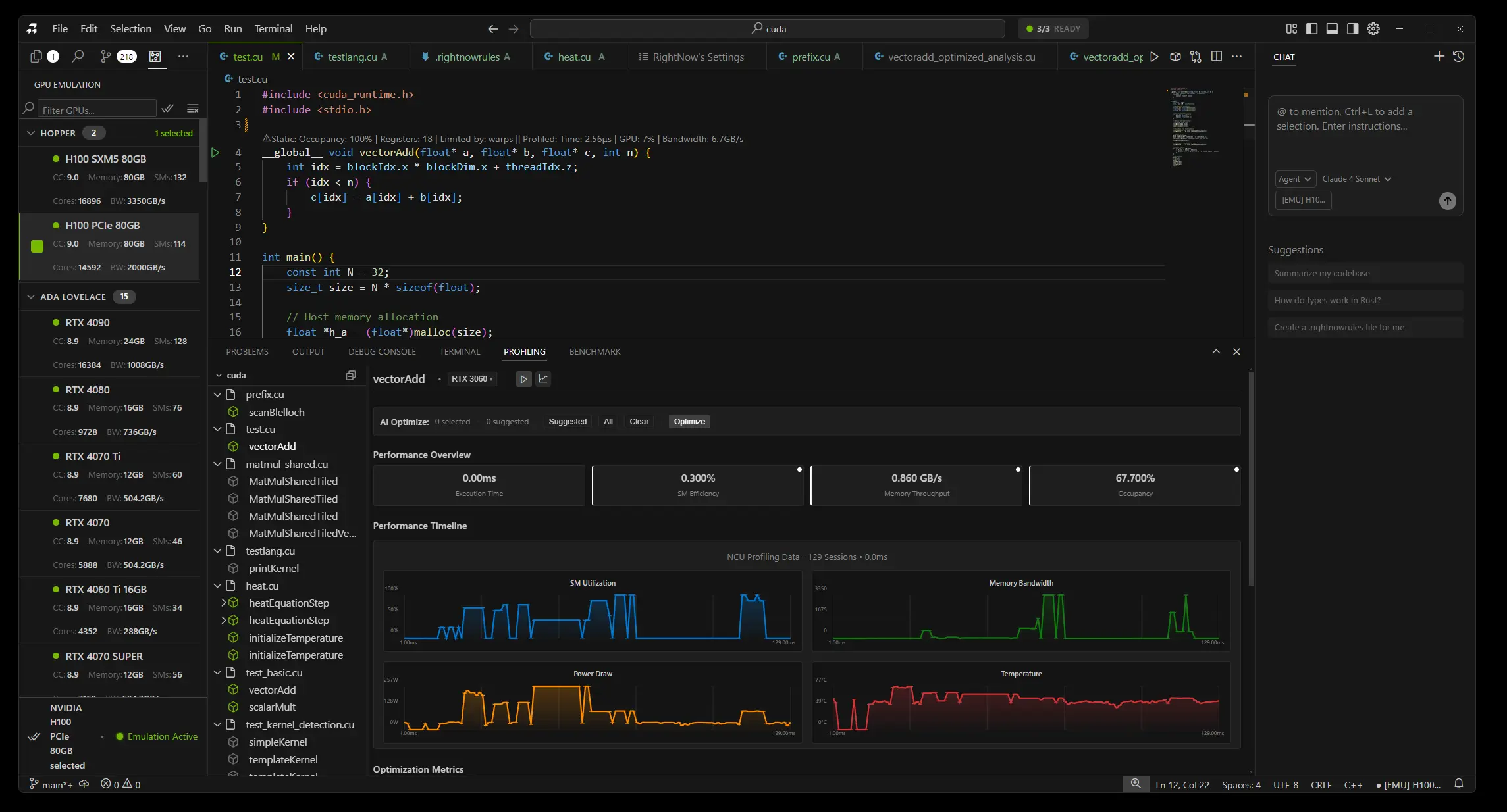
What it looks like in the editor
Write a CUDA kernel. Click a button. Pick your GPUs. Get results:
┌──────────────────────────────────────────────────────────────┐
│ RightNow AI: GPU Emulation Interface │
├──────────────────────────────────────────────────────────────┤
│ │
│ __global__ void myKernel(float* data, int n) { │
│ // ... kernel code ... │
│ } │
│ │
│ [Emulate Kernel ▼] Select GPUs: [All] [Hopper] [Ampere] │
│ │
│ Results (sorted by performance): │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ H100 (80GB) 1.2ms 🟢 92% efficiency │ │
│ │ RTX 4090 1.8ms 🟢 87% efficiency │ │
│ │ A100 (80GB) 2.1ms 🟢 84% efficiency │ │
│ │ V100 (32GB) 3.4ms 🟡 68% efficiency │ │
│ │ RTX 3080 4.2ms 🟡 61% efficiency │ │
│ │ GTX 1060 12.8ms 🔴 34% efficiency ← FIX! │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ Click any GPU for detailed metrics and recommendations │
│ │
└──────────────────────────────────────────────────────────────┘See the whole landscape instantly. GTX 1060 is red? Click it. Probably low occupancy. Bump your block size. Re-emulate. Green.
What doesn't work yet
It's not perfect:
Dynamic parallelism. Kernels launching kernels. Haven't figured out how to trace the whole call graph yet.
Multi-GPU. Only does single-GPU kernels right now. No NCCL, no peer-to-peer transfers.
Tensor cores. We model them as fast FP16, but not perfectly. Hopper and Ada have tons of tensor tricks we don't capture.
Tiny kernels. Under 1 microsecond, overhead dominates. Accuracy drops to 85-90%.
Working on all of these. Multi-GPU is next.
Try it
It's built into RightNow AI. Write a kernel, click emulate, see results for 50+ GPUs.
┌──────────────────────────────────────────────────────────────┐ │ What You Get │ ├──────────────────────────────────────────────────────────────┤ │ │ │ ✓ Emulate 50+ GPU models without owning them │ │ ✓ 98-99% accuracy on execution time │ │ ✓ Results in 100-500ms per GPU │ │ ✓ Detailed metrics and recommendations │ │ ✓ Architecture database (Hopper → Pascal) │ │ ✓ Compare performance across generations │ │ ✓ Catch bugs before deployment │ │ ✓ Save $1000s in cloud costs │ │ │ │ Works on Windows & Linux (x64 & ARM64) │ │ Free for personal use │ │ │ └──────────────────────────────────────────────────────────────┘
Zero setup. Runs on CPU (no GPU needed). Test anywhere.
Why it matters
Five years ago, everyone had a GTX 1080. Now? Someone has a 1060, someone has a 4090, cloud runs H100s. Your code needs to work on everything.
This tool makes that possible. Without spending $90,000 a year renting GPUs you'll never own.
Jaber